|
(IDE is for “integrated development
environment")
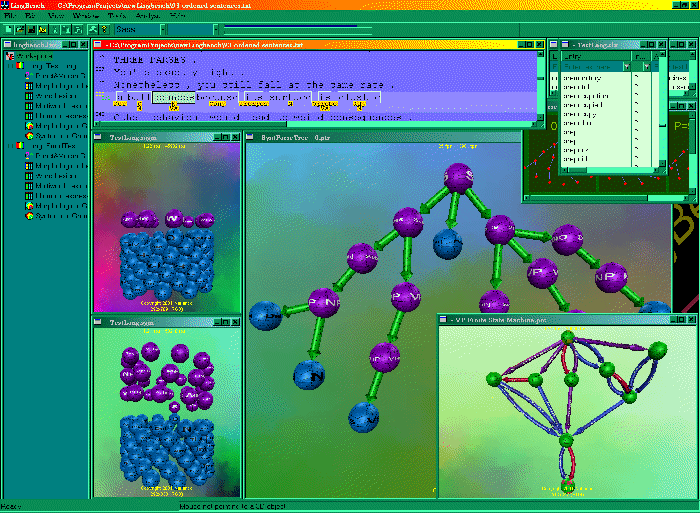
↑ Figure 1:
A typical view when working with LingBench IDE™
What is LingBench IDE?
LingBench IDE is an Integrated Development
Environment for Linguists and Computer Linguists to Model a
Natural Language by describing the morphology, the syntax, the
lexical and other aspects of a language in detail. These high
quality models (files) can then afterward be used by other
programs so that a computer can handle these aspects of
the language autonomously . The innovative and
intuitive user interface of LingBench IDE™, based on patented technology,
is a very efficient and unsurpassed powerful way to handle
almost every aspect of computer linguistics.
See
also LingBench
IDE Light.
See
also FAQ and Plaform&Pricing
further on this page
Grammar Designing
Features:
-
Backbone is RTN (Recursive Transition Network), which
is conceptually compatible with almost every other modern grammar-modeling
paradigm, including BNF.
-
But
the RTN backbone has been very much further elaborated,
first into ATN (Augmented Transition Network), and far
beyond, including probability everywhere and complete
programs can be associated with any transition. See below.
-
Free choice of word classes, phrases, features and
their names and properties, all of which can be changed easily at any time.
-
Phrases are rich entities that can (but don’t need
to) have arbitrary ‘variables’ (e.g. linguistic features or booleans) to coordinate between words or
wordgroups or for semantic purposes
-
Transitions can have attached conditions and actions
acting on features of words and phrases or, if required, complete complex
programs.
-
Automatic or manual probability assignment for
transitions and inherent handling of these probabilities up to the parse forest.
Each surviving parse gets a probability that a together
add up to 100% for one input sentence.
-
Intuitive 3D graphic Phrase Definition by mouse
clicking and dragging.
-
Virtually no upper limit on the complexity of models.
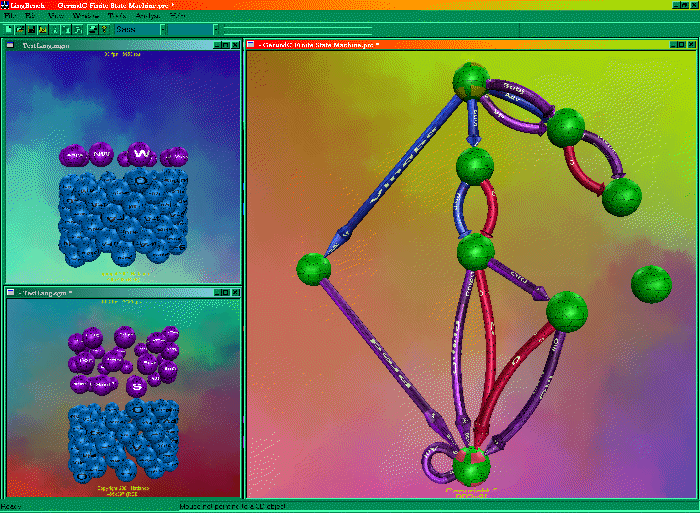
↑ Figure
2: You
can choose to edit your grammar using a 3D graphical user
interface. In the View on the right, nodes are added by
clicking left, transitions are added by dragging from one node
to another. In this way you define paths to go from the upper
node to the lower node, thus defining the blueprint of a
Phrase definition. Both
Views on the left represent separate grammars in their own:
the upper one is the morphology grammar, the lower one the
(traditional) syntactic grammar. Such grammars contain
wordclasses (or morpheme classes), shown as blue balls, and
phrases, shown as purple balls. When you click on a Phrase
ball, a View of its 'inside' is shown, like the one on the
right. You can then go on editing the 'inside' of the
particular Phrase. Clicking inside one of the left grammar
views allows adding arbitrary new classes and phrases, and
much more.
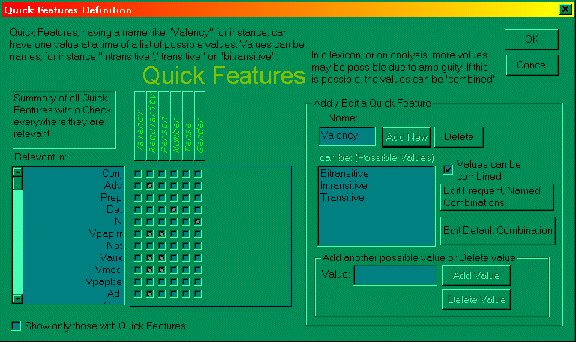
↑ Figure
3: You
can freely choose which features you want to be known in the
grammar, their names, values and further behavior, and in
which (word/morpheme)Classes and Phrases they are relevant.
Morphology Modeling
Features:
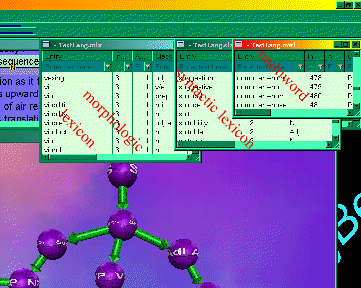
↑ Figure
4: The
three levels of lexicon that can be in a language model
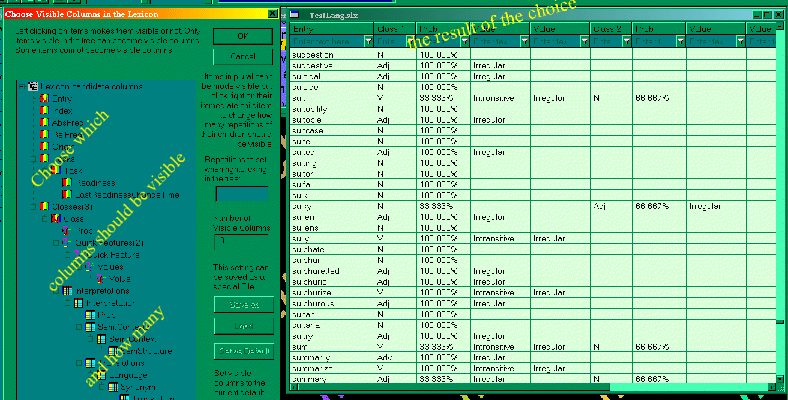
↑ Figure
5: In
a lexicon, large amounts of information can be present, which makes it difficult to
visualize everything in columns. In LingBench IDE, you can easily change which
information should actually be displayed in the columns, by selecting, in a dialog box, the items
to be shown from a tree that contains all available information, and their
repetitions (for instance, at a given moment, 3 columns show the possible
wordclasses. If
you want more such columns or none of that kind, the view can be changed by
tuning the settings in the dialog box on the left).
Lexicon Development
Features:
-
three levels of lexica: morphologic, syntactic and
multiword
-
lexica can easily be imported from, or merged or
enriched with external sources
-
easy semi-automatic additions to lexicon from corpora
containing unknown words
-
origin of entries in the lexicon is kept track of,
per word or set of words that were imported together
-
Several 'Tasks' can be defined on a lexicon. Each task
contains a description of which properties of which type of entries are to be
edited. As the task is carried out (in one or more sessions), the readiness
state of each such entry is kept track of. A task allows modifying specific
properties of these entries very efficiently and quickly. An example of a
simple task: filling out the correct gender of all Nouns that begin with “pre”
and that originated from a corpus of BBC news texts.
-
Rich and intuitive set of possibilities to
see only a 'filtered' selection of a lexicon, in simple 'DOS'
style or with complex regular expressions
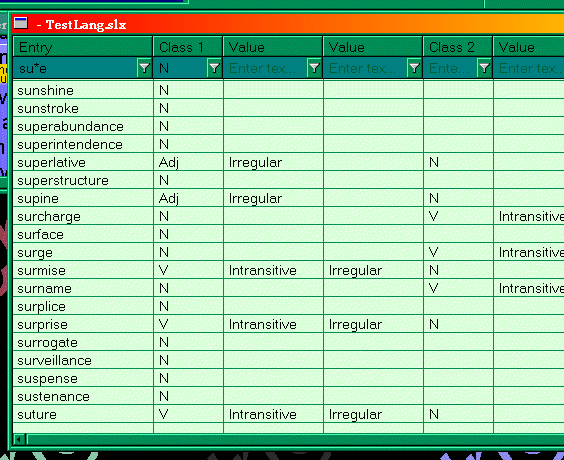
↑ Figure
6: Setting
filters on top of the columns in a lexicon view. Remark that
filters apply to sibling columns as well.

↑ Figure
7: Defining
one
or more simultaneous "Lexical Tasks" 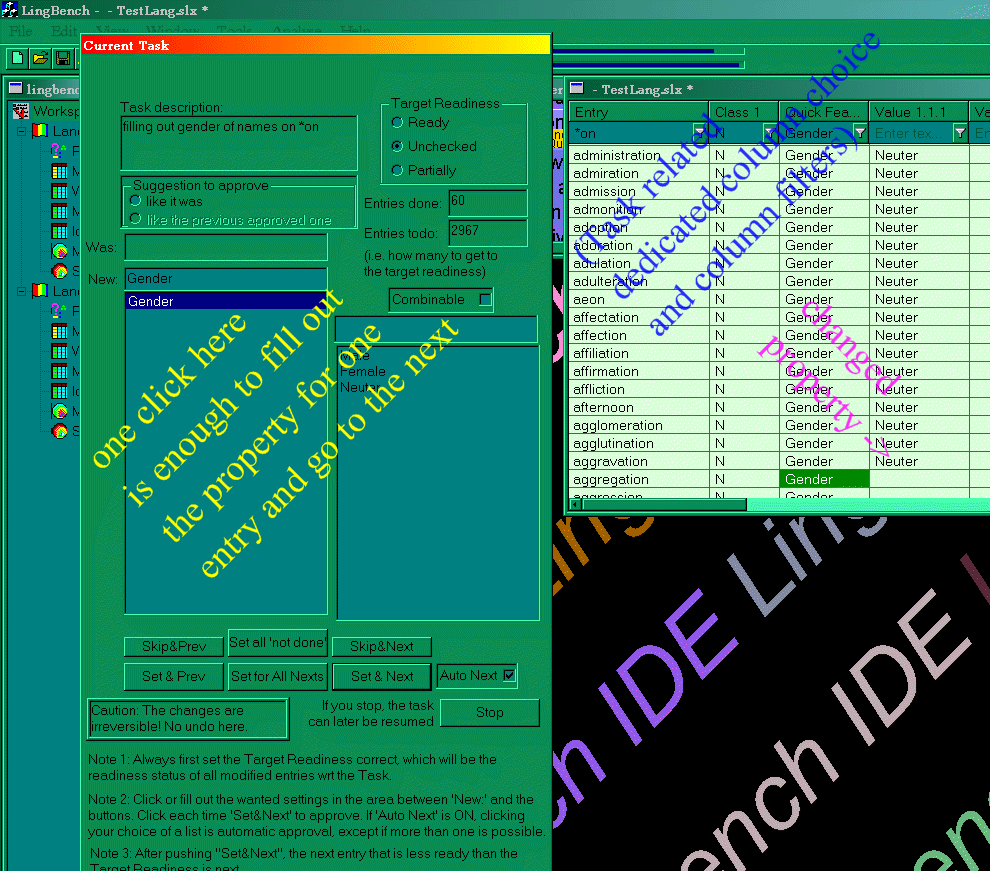
↑ Figure
8: A
typical view of a lexical task session. In many cases, just
one mouse click per entry property allows to fill out Task
specific properties in the most efficient way possible. The
lexical task can be carried out in multiple sessions and
target a specific readiness level.
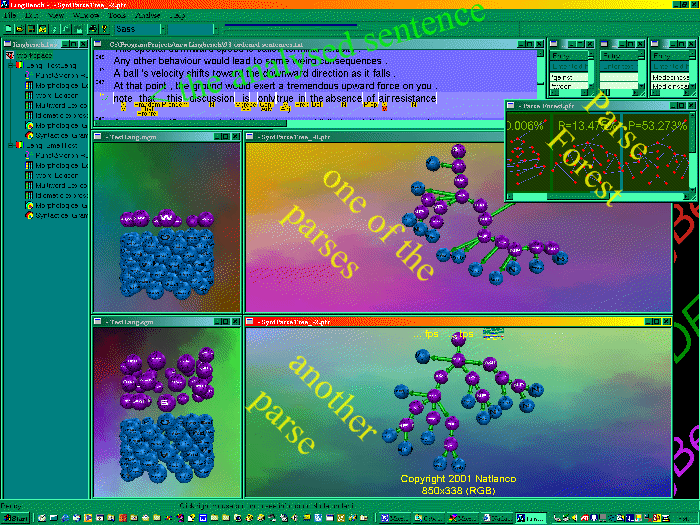
↑ Figure
9: The
integrated parser immediately shows the effect of the latest
model changes on sentence in the testcorpus. By clicking on
parse tree summaries in the parse forest view one or more
parse trees can be examined in detail.
Model Testing/ ‘Debugging’
Features:
One of the major advantages is that the state of the
language model can be tested on a testtext, a sentence or a separate wordform,
all from within the same environment.
-
Graphic syntactic analysis (parse) displayed as a
(3D) tree.
-
Easy browsing among the resulting parse trees in the
graphic overview of the parse forest
-
For syntactic as well as for morphologic analysis
-
Statistics on parsibility of the sentences in the
testtext
-
Easy swapping of test-texts
-
Informative per word annotation of analysis results
(See above figure).
Editor properties:
-
Workspace concept: clear overview of the languages
and their components
-
Easy resumption where your work stopped last time.
-
Efficient mouse use: Right clicking makes a menu pop
up with the commands that are relevant for the place pointed to, so no
unnecessary far mouse moves.
-
Undo/Redo facility of multiple editing steps
-
Autosaving of Language models every few minutes or
every few editing actions (so if a crash or other severe problem occurs on your
computer, no significant amount of work can be lost).
-
Language models can be saved as a whole, or
subaspects like separate lexica can be saved or loaded separately. Also, parse
forests and trees can be saved.
-
If
the user prefers so, many 3D views can be toggled to textual display
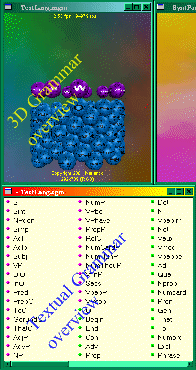
↑ Figure
10: Toggling
between 3D and textual grammar overview, depending on the preference of the
user
Languages and compatibilities:
-
Language independent software
-
Highly language universal
-
Unicode version forthcoming

↑ Figure
11: the LingBench IDE opening screen
FAQ
(version
September 2002)
Q: Can I evaluate LingBench IDE for free?
A: Yes: download the Light version to do this. You can
evaluate it during four weeks for free.
Q: Can I start developing from my own
old lexicon?
A: Yes, if you can export
your lexicon to an ASCII file with TAB or similar separators. You can keep your old
wordclass names, but you should define them first into the grammar, before
importing the lexicon.
Q: Can I recycle my old grammar / morphologic
models?
A: Importing external
formats for grammar isn’t available in version 1.1 yet, but you can quickly
enter (draw) the schemes of your phrases or BNF rules. You soon will find out
that the LingBench IDE approach gives you a feeling of insight and overview on
your old grammar, particularly if it was text based.
Q: It all looks fancy, but is this a serious
language modeling system?
A: What you can’t see is
an extremely powerful, versatile and innovative battery of new patented
technologies behind the screens, for instance the integrated screamingly fast
parser. But why should all this be packed in brown paper?
Q: 3D and animation
everywhere, but is this functional? Can I work in textual mode?
A: For complex transition
schemes defining complex phrases, 2D is not satisfactory as many crossing
arrows confuse the viewer. Only 3D and animation together are extremely
efficient in letting the user keep overview, which is of paramount importance
for designing high quality models.
The 3D view of parse trees is at present not strictly
necessary, but in future versions, more information will be shown with the
trees, which isn’t evident in 2D. For grammar overview windows, the 3D can be
toggled with a textual, list-like view, which often can be handier.
Working completely in a textual mode to design the
grammar is in general not efficient and can easily lead to inconsistencies, so
it’s against the LingBench IDE philosophy and not supported at present.
Q: LingBench IDE seems all
right, but is there support, and what guarantees are there for the future?
A: There is support
included in the standard license, including the right to get a next version
for free, and a guarantee that all well documented and repeatable
problems will be solved in the new version, except the
platform/installation dependent ones. Extended support is subject of a separate
contract.
LingBench IDE has been conceived in 1996 and the
original designers are still in Natlanco. Natlanco, 100% owned by them, has a
strategy of long-term stability and is extremely cautious with financial risks.
Q: Is LingBench IDE a
stable product?
A: LingBench IDE is a
highly complex product, but is surprisingly small as a program. This is because
of the quality of code. We did our very best to get LingBench IDE as reliable
as possible, but also we have included functionality to safeguard your work
regularly, so that in case of a crash, you easily can recover the situation of
a few minutes ago. There is also regular (invisible) internal consistency
checking.
Q: Is there a manual?
Where can I learn to use LingBench IDE?
A: There is an extensive
manual. No courses are given yet, but this can be discussed.
Q: When will the Unicode
version be available? Will that system be compatible with Chinese/Japanese/Arabic?
A: The Unicode version
just missed the LangTech2002 conference.
Chinese and Japanese are compatible with the present
version if Pinyin or another ASCII transcription system is used. Compatibility
with Arabic can be expected in Q4 of 2002.
Q: What can I do with the
language models made with LingBench IDE?
A: Natlanco also sells its LingBench SDK product, a
software development kit, which
contains a software module that can ‘understand’ the format of a Language Model
made with LingBench IDE. SDK stands for “software development kit”.
Typically, clients for this product
develop end application software, like machine translators, search engine
systems, grammar/spelling control and correction etc… (see the Natlanco site,
“Quick Guide”), and use this (extremely fast) module to do the linguistic
analysis of their incoming sentences.
The current SDK is for Windows2000 and XP only. Compatibility
with other platforms can be developed on demand.
Q: Does Natlanco itself
also sell Language Models? Which ones?
A: Natlanco has several
language models, but currently only a model for English is commercialized.
Q: To which domains is LingBench IDE relevant?
A: LingBench IDE is relevant for people and companies who are looking for:
(keyphrases)
-
Natural Language Processing Software
(NLP Software, NLP Tools)
-
Language Modeling Software
-
Computer Linguistics Software
-
Linguistic analysis software
-
Grammar designing tool
-
Grammar modeling tool
-
Natural language engineering software
-
Natural language engineering tools.
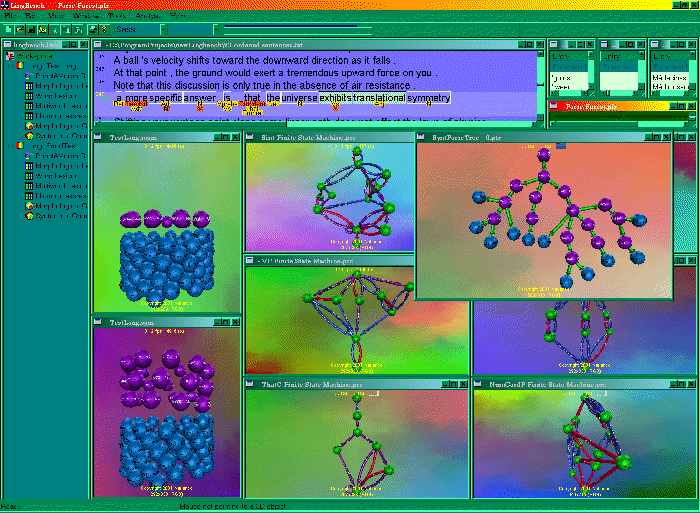
↑ Figure
11: With
LingBench IDE there is virtually no upper limit to the
quality and complexity of the language model. And the
innovative user interface allows unsurpassed levels of
efficiency and productivity. The language models can either
be exported to your own format or, much better, be used by
the engines in the LingBench SDK package, which you can build
in in your own application.
Platform
&Requirements:
-
PC, minimally 1 GHz, 256 MB RAM, 512MB recommended
-
Windows2000 or XP
-
Screen resolution: min 1024x768, 16 bit
colors (high color)
User License:
-
One installation on one PC (academic license: on 3 PCs)
-
Unlimited use (in time) after key code exchanged
-
Support through e-mail to solve fully documented
repeatable problems
-
Right to get next version of same product for free,
including the fixes of all documented repeatable problems (except installation
or computer dependent problems) you correctly reported within the first 2
months after license purchase.
-
Manual + next update of manual (update
by e-mail)
Pricing
-
Professional Version 1.1: € 2499 per licensed installation
-
Professional Version 1.1 for Academic use: € 2499 for 3 licensed installations
-
Extended Service for Professional Version 1.1, during first 3 months: € 1000
-
Light Version
1.2: downloadable shareware, 4 weeks free, then € 199 per licensed installation (download available from
May 1, 2003 onward)
|




